

2419 位用户此时在线
- 本站自动实时分享网络热点
- 24小时实时更新
- 所有言论不代表本站态度
- 欢迎对信息踊跃评论评分
- 评分越高,信息越新,排列越靠前

晚上有机会坐下来细看DS公布的数据,再次被深深震惊了。
DeepSeek在线服务的运行数据
英文版本见公布的Github链接。
所有DeepSeek-V3/R1推理服务均在H800 GPU上运行,且推理精度与训练一致:
🔹 矩阵乘法和调度传输采用 FP8 格式(与训练对齐)。
🔹
时政
(
twitter.com
)
晚上有机会坐下来细看DS公布的数据,再次被深深震惊了。
DeepSeek在线服务的运行数据
英文版本见公布的Github链接。
所有DeepSeek-V3/R1推理服务均在H800 GPU上运行,且推理精度与训练一致:
🔹 矩阵乘法和调度传输采用 FP8 格式(与训练对齐)。
🔹 核心MLA计算和合并传输采用BF16格式,确保最佳性能。
推理资源调度
🔹 白天推理服务负载高,夜间负载低,因此我们:白天启用所有推理节点。
🔹 夜晚减少推理节点,将部分资源转用于研究和训练。
过去 24 小时(UTC+8 2025 年 2 月 27 日 12:00 PM - 2 月 28 日 12:00 PM):
🔹 V3 + R1 推理服务的峰值节点占用:278 个,平均 226.75 个节点(每个节点包含 8 个 H800 GPU)。
🔹 假设H800 GPU租赁成本为$2每小时,则每日成本为$87,072。
DeepSeek V3/R1 24小时统计数据
2025 年 2 月 27 日 12:00 PM - 2 月 28 日 12:00 PM(UTC+8):
🔹 总输入tokens:6080 亿(其中 3420 亿(56.3%)命中磁盘 KV 缓存)。
🔹 总输出tokens:1680 亿。
🔹 平均输出速度:20-22 tokens/s,平均KV缓存长度:4989 tokens。
🔹 每个H800节点吞吐量:预填充阶段:73.7k tokens/s(包括缓存命中)
🔹 解码阶段:14.8k tokens/s
📌 所有请求来源:网页、APP 和 API。
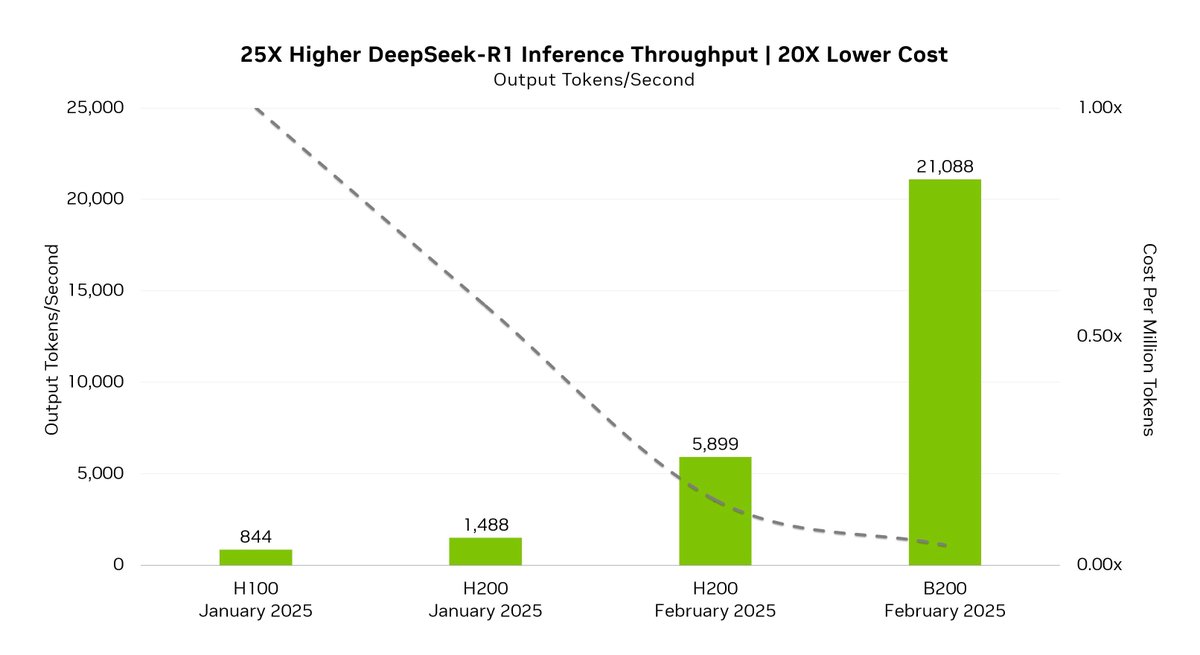
我们简单地取高峰的278个节点,一天24个小时总输出1680亿个,平均每个节点(8卡H800)每秒至少能输出 168000000000/278/24/3600 = 6995t/s。
我们简单把DS和之前NV官方的贴文合起来解读一下。
https://t.co/tNyZaXkkfm
NV在8卡H200节点上优化版本的性能(5899t/s)只有DS在8卡H800节点性能的~84%。
说到这里,我们得解释一下:H200的内存带宽显著优于H800。H200采用了最新的HBM3e内存技术,其带宽显著提升 —— 公开资料显示,其内存带宽可达到约4.8 TB/s,而H800所使用的HBM3内存带宽限制,通常只有大约1.7 TB/s左右。众所周知,HBM内存带宽对AI训练和推理性能的提升尤为关键。
说到这里,我只能说,DS团队的工程能力简直令人发指。
不由地想,现有的大规模算力基础设施(A100,H00)虽然已经投入使用多年,但其潜力远未完全释放。
所以,对大规模Capex投入的厂商来说,当务之急是继续大规模投入?还是应该投入工程力量挖掘潜力?
点击图片查看原图