
在闭源超大型模型盛行的时代背景下,微软选择了一条不同的道路,专注于开发“小而美”的oss模型,正如phi和Wizard。
昨天,微软放出开源2.7B的phi-2,效果媲美超过自己25倍参数规模的llama-2 70B。事实上,自phi-1和phi-1.5起,phi系列在过去半年中已迭代了三次。phi的卓越表现源于半年前发表的论文…
时政
(
twitter.com
)
在闭源超大型模型盛行的时代背景下,微软选择了一条不同的道路,专注于开发“小而美”的oss模型,正如phi和Wizard。
昨天,微软放出开源2.7B的phi-2,效果媲美超过自己25倍参数规模的llama-2 70B。事实上,自phi-1和phi-1.5起,phi系列在过去半年中已迭代了三次。phi的卓越表现源于半年前发表的论文 Textbooks Are All You Need,该论文的核心观点是注重数据的质量。
在探索如何提升数据质量的过程中,作者采用了一种富有哲学意味的方法,即将语言模型训练的过程人性化。比如,在我们学习编程时,如果所用的学习材料缺乏清晰的结构大纲,示例代码频繁调用来源不明的外部模块,或者常量与变量的定义混乱且缺乏实际意义,那么学习效率自然会受到影响。
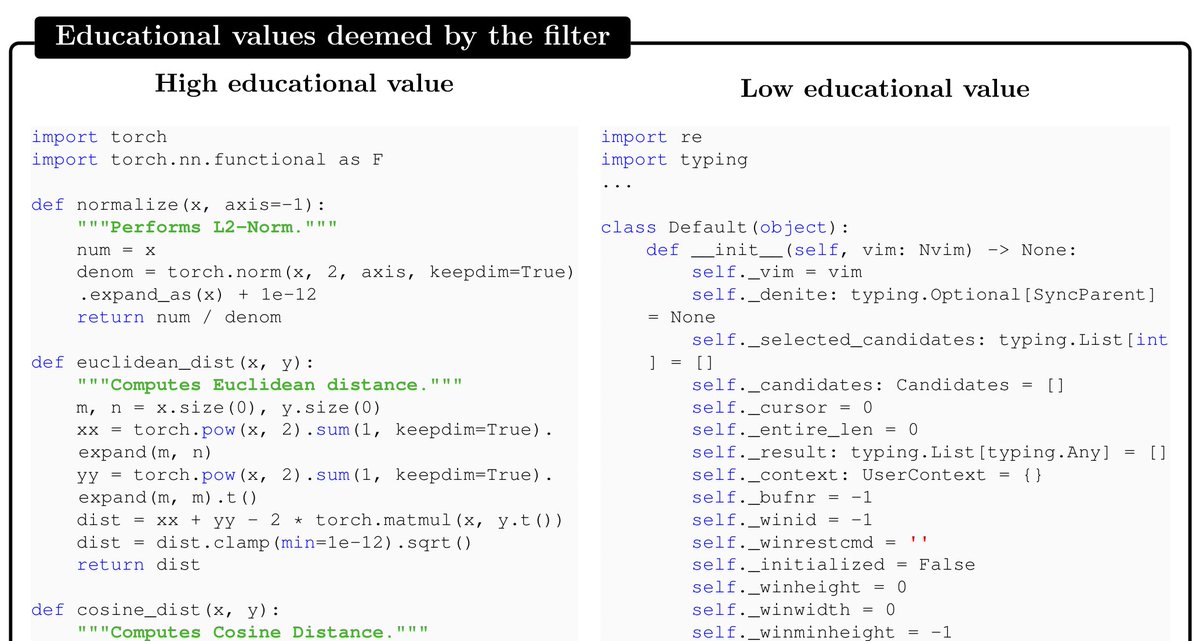
下图展示了高质量数据vs低质量数据。
当前语言模型在预训练阶段所使用的语料普遍存在一些问题,如高噪声、内容模糊不清以及话题分布的不均匀等。作者针对这些问题,有意识地选择并生成高质量数据,力求让数据集像教科书Textbook一样,具备清晰度、独立性、指导性以及话题上的平衡性。这种方法使得即便是小型模型,也能经过精细训练,在特定任务上达到大型模型的效果。
值得注意的是,phi的训练过程中未采用任何指令微调(instruction finetuning)或强化学习(RLHF)。这意味着phi更像是一个纯粹的文本补全模型。因此,在使用提示(prompt)引导phi时,它可能不会完全按照预期执行,例如不会按指令输出JSON格式。这种特性使得phi更适合作为专家模型,用于特定的下游任务。
在微软的另一条expert model路线,Wizard系列也非常出色。
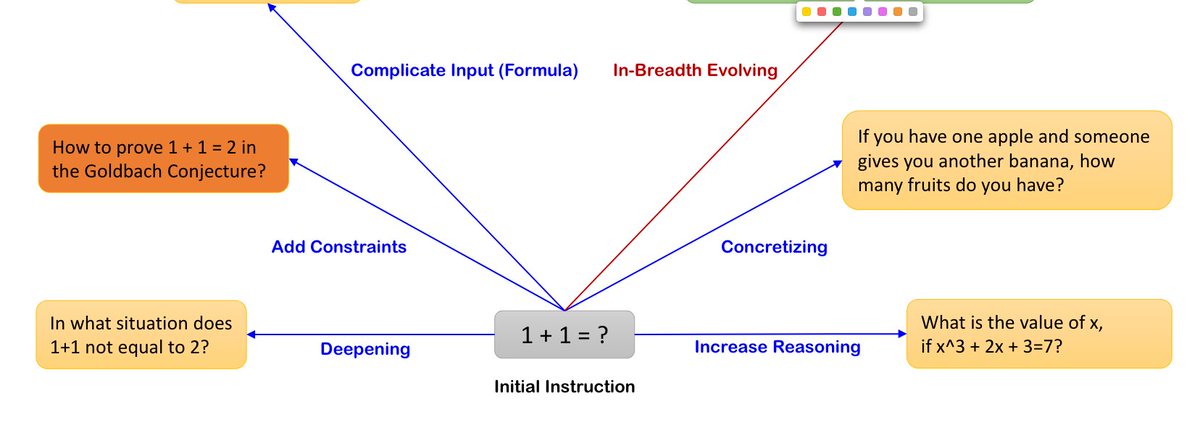
Wizard模型的核心理念同样也蕴含了深刻的哲学思考,特别是它所引入的“Evol-Instruct”概念,这在很大程度上借鉴了演化论的思想。
具体来说,当人们学会基础的概念,比如“1+1=2”之后,随着时间的推移,他们的思维会经历一种深度(In-Depth)和广度(In-Breadth)的演化过程。例如,他们可能会开始思考“在什么情况下1+1不等于2?”或“在真空中光速是多少?”等更深入或更广泛的问题。这种思维的演化过程正是Wizard模型试图模拟的核心要素。
对于语言模型而言,这种深度(In-Depth)和广度(In-Breadth)的指令演化使得模型能够解放思想、与时俱进,并把握遵循事物发展的客观规律,做到了举一反三。这种能力使得模型能够在学习一个概念后应用到其他相关领域,从而能够遵循更加复杂和多样的指令,完成不同的任务。
基于Evol-Instruct理念,Wizard系列的oss模型在大模型任务的三大核心领域——instruction(WizardLM)、math(WizardMath)和code(WizardCoder),都表现出色。值得一提的是,Wizard系列模型都是通过instruction tuning得到的专家模型,所以,在遵循指令方面表现稳定。
此时,从phi和Wizard的发展来看,微软似乎并没有在闭源大型模型领域投入太多,而是在开源的专家(小型)模型上下了大量功夫。微软专注于从文本补全到推理、数学、编程等细分任务的“小而美”发展。这些工作对于我们构建自己的下游专家模型提供了重要的参考和启示。
Textbooks Are All You Need https://t.co/g91flOIRnU
WizardLM、WizardMathWizardCoder
https://t.co/kWbDViSRpY
点击图片查看原图

点击图片查看原图

点击图片查看原图
点击图片查看原图

