
Kimi和DeepSeek的新模型这几天内同时发布,又是一波让人看不懂的突飞猛进,硅谷的反应也很有意思, 已经不再是惊讶「他们是怎么办到的」,而是变成了「他们是怎么能这么快的」,就快走完了质疑、理解、成为的三段论。
时政
(
twitter.com
)
Kimi和DeepSeek的新模型这几天内同时发布,又是一波让人看不懂的突飞猛进,硅谷的反应也很有意思, 已经不再是惊讶「他们是怎么办到的」,而是变成了「他们是怎么能这么快的」,就快走完了质疑、理解、成为的三段论。
先说背景。大模型在运作上可用粗略分为训练和推理两大部分,在去年9月之前,训练的质量一直被视为重中之重,也就是通过所谓的算力堆叠,搭建万卡集群甚至十万卡集群来让大模型充分学习人类语料,去解决智能的进化。
为什么去年9月是个关键的转折点呢?因为OpenAI发布了GPT-o1,以思维链(Chain-of-Thought)的方式大幅提高了模型能力。
在那之前,行业里其实都在等GPT-5,以为一年以来传得沸沸扬扬的Q*就是GPT-5,对o1这条路线的准备严重不足,但这也不是说o1不能打,它的强大是在另一个层面,如果说训练能让AI变得更聪明,那么推理就会让AI变得更有用。
从o1到o3,OpenAI的方向都很明确,就是变着法儿奔向AGI,一招不行就换另一招,永远都有对策,大家平时对于OpenAI的调侃和批评很多,但那都是建立在高预期的前提下,真不要以为OpenAI没后劲了,事实上每次都还是它在推动最前沿的技术创新,踩出一条小径后别人才敢放心大胆的跟上去。
AI大厂们一直不太承认训练撞墙的问题,这涉及到扩展法则(Scaling Law)——只要有更多的数据和算力,大模型就能持续进步——有没有失效的问题,因为可被训练的全网数据早就被抓取殆尽了,没有新的知识增量,大模型的智能也就面临着无源之水的困局。
于是从训练到推理的重点转移,成了差不多半年以来最新的行业共识,推理采用的技术是强化学习(RL),让模型学会评估自己的预测并持续改进,这不是新东西,AlphaGo和GPT-4都是强化学习的受益者,但o1的思维链又把强化学习的效果往前推进了一大步,实现了用推理时间换推理质量的正比飞跃。
给AI越充分的思考时间,AI就能越缜密的输出答案,是不是有点像新的扩展法则?只不过这个扩展在于推理而非训练阶段。
理解了上述背景,才能理解Kimi和DeepSeek在做的事情有什么价值。
DeepSeek一直是「扮猪吃老虎」的角色,不但是价格战的发起者,600万美元训练出GPT-4o级模型的测试结果,更是让它一战成名,而Kimi正好相反,它的产品能力很强,有用户,甚至还为行业贡献了足够的融资八卦,但在科研方面,除了都知道杨植麟是个牛逼的人之外,其实还是不太被看到。
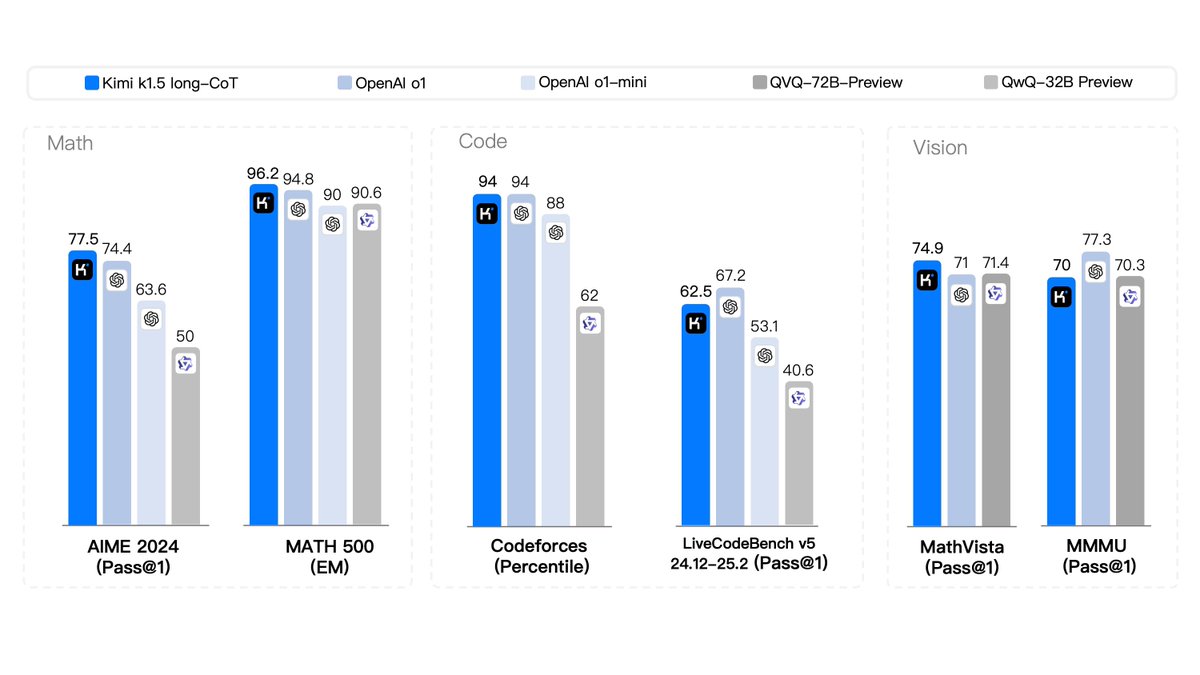
这次就不一样了,DeepSeek不再是一枝独秀,Kimi也把肌肉秀到了人家脸上,Kimi k1.5满血版在6项主流基准测试里和o1同台竞赛,拿到了3胜1平2负的结果,已经完全称得上是平起平坐了。(1/2)
点击图片查看原图

点击图片查看原图

