
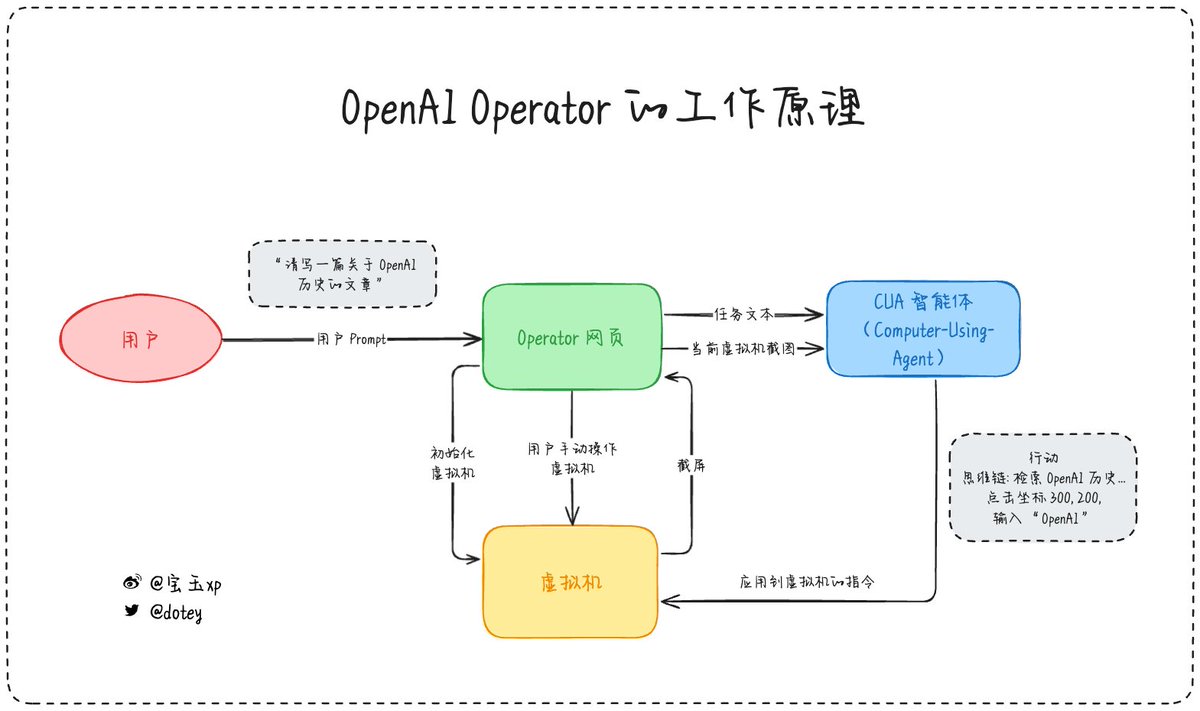
OpenAI Operator 的工作原理
为 Operator 提供支持的是 Computer-Using Agent (CUA),它结合了 GPT-4o 的视觉能力与通过强化学习获得的高级推理能力。
当用户向 Operator 网页发送请求的时候,Operator 会启动一个用户专属的虚拟主机(这也可能是为什么现在只能面向 pro
IT技术
(
twitter.com
)
OpenAI Operator 的工作原理
为 Operator 提供支持的是 Computer-Using Agent (CUA),它结合了 GPT-4o 的视觉能力与通过强化学习获得的高级推理能力。
当用户向 Operator 网页发送请求的时候,Operator 会启动一个用户专属的虚拟主机(这也可能是为什么现在只能面向 pro 用户的原因之一),这个虚拟机上装了一个 Chrome 浏览器,并且 Session、Cookie 会一直给你保留。
虚机的截图会同步到 Operator 网页,所以网页上可以实时看到网页操作的情况。CUA 根据系统提示词+用户输入的任务+当前任务状态+截图会借助 CoT 思考生成可以执行的 Actions,由于系统提示词包含了一系列品目操作的指令,比如鼠标移动、点击、拖动等等,最终这些 Action 会编程屏幕操作的指令,这样 CUA 就可以操作屏幕了。
只是我没搞明白的是,多模态是怎么精准获取坐标位置的?
CUA 通过处理原始像素数据来理解屏幕上发生的内容,并通过虚拟的鼠标和键盘来执行操作。它能够进行多步骤的任务导航、处理错误并适应意外变化。这让 CUA 能够在各种数字环境中行动,例如填写表单、浏览网站,而无需使用专门的 API。
在接收到用户指令后,CUA 通过一个融合感知、推理和动作的迭代循环来执行操作:
- 感知(Perception):从计算机截取的屏幕截图会加入到模型的上下文中,为模型提供当下计算机状态的视觉快照。
- 推理(Reasoning):CUA 使用链式思考(chain-of-thought)来推断下一步的行动,同时考虑当前和过去的屏幕截图及操作。这种“内在独白”有助于模型评估观察结果、跟踪中间步骤并进行动态调整,从而提升任务完成度。
- 动作(Action):模型执行点击、滚动或键入等操作,直到它判断任务已完成或需要用户进一步输入。虽然大多数步骤能自动完成,但在遇到敏感操作(例如输入登录信息或回答 CAPTCHA 等)时,CUA 会请求用户进行确认。
点击图片查看原图

